ARCHITECTURE¶
Parallelization¶
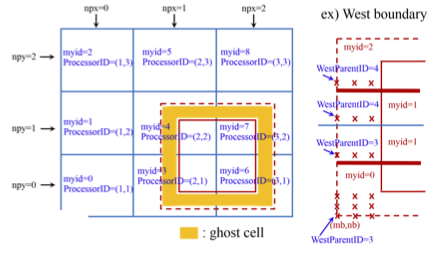
In parallelizing the computational model, we used a domain decomposition technique to subdivide the problem into multiple regions and assign each subdomain to a separate processor core. Each subdomain region contains an overlapping area of ghost cells, three-row deep, as required by the fourth order MUSCL-TVD scheme. The Message Passing Interface (MPI) with non-blocking communication is used to exchange data in the overlapping region between neighboring processors. Velocity components are obtained by solving tridiagonal matrices using the parallel pipelining tridiagonal solver described in Naik et al. (1993).
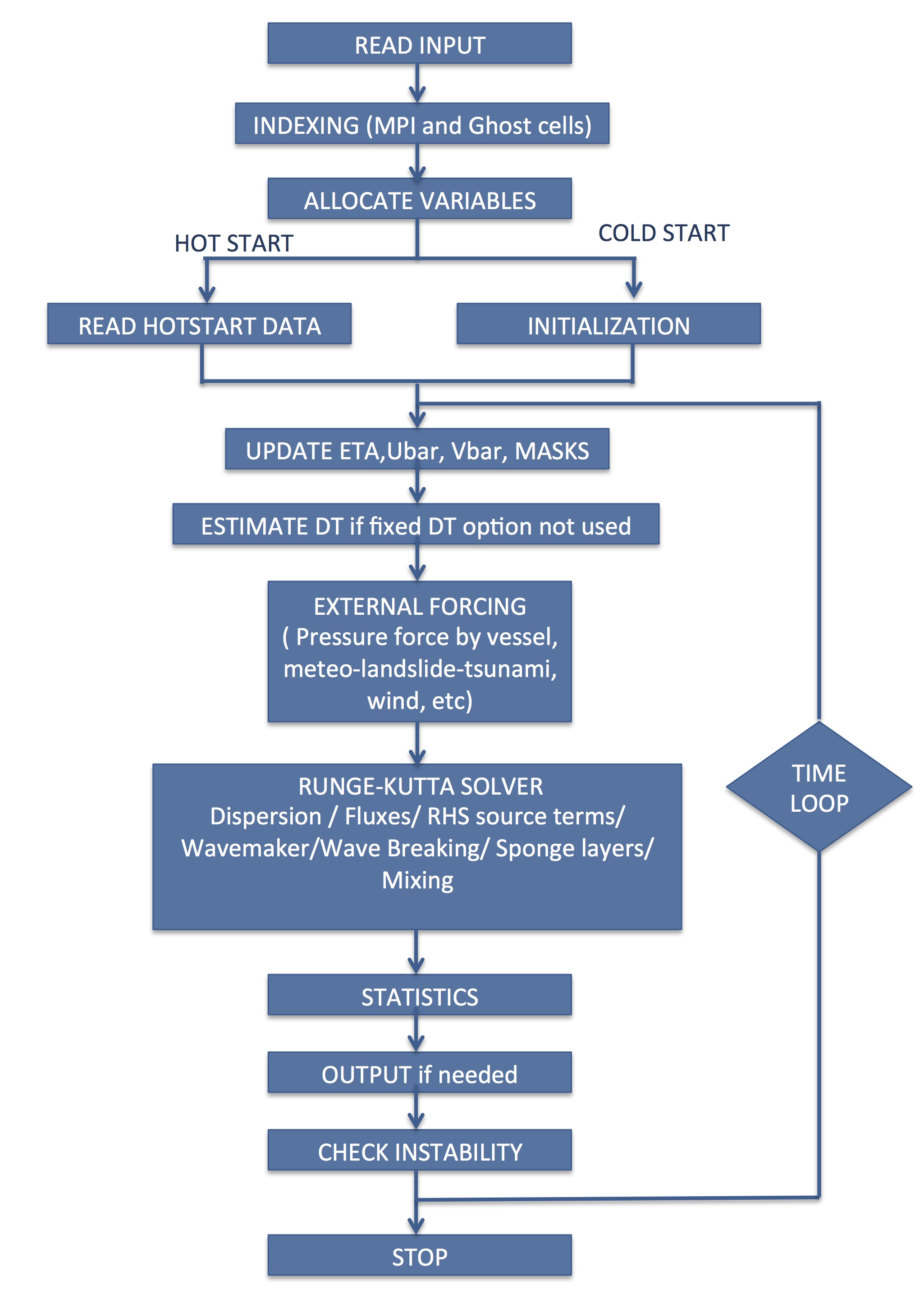
Flow chart¶
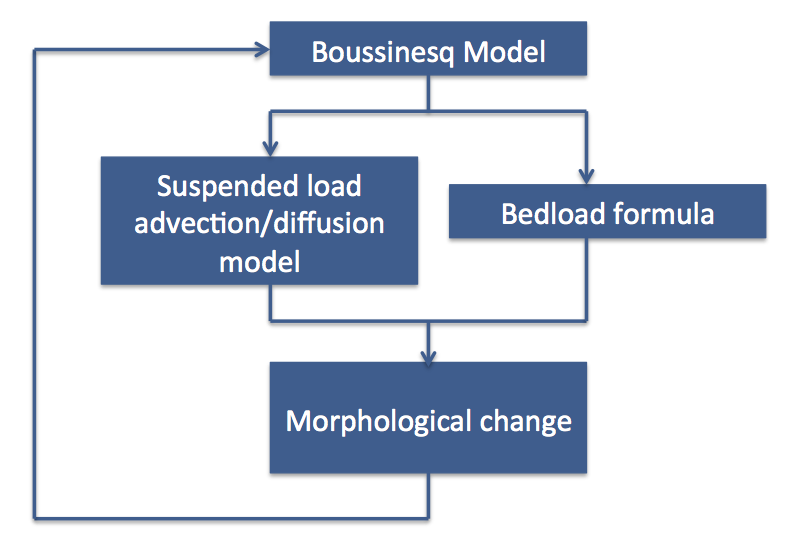
Nesting structure¶