SWAN-SHORECIRC COUPLING AND PARALLELIZATION¶
For the SHORECIRC code, we used a domain decomposition technique to subdivide the problem into multiple regions and assign each subdomain to a separate processor core. Each subdomain region contains an overlapping area of ghost cells, three-row deep, as required by the highest-order ( the fourth order) MUSCL-TVD scheme in the model. The Message Passing Interface (MPI) with non-blocking communication is used to exchange data in the overlapping region between neighboring processors.
For the SWAN code, we used the existing domain decomposition scheme which is slightly different from the SHORECIRC code. The version 40.51AB of SWAN uses a single-direction domain decomposition and takes into account number of dry points in the grid splitting. Because of the different domain decomposition between SHORECIRC and SWAN, it is difficult to directly pass variables between the decomposed domains. We now used a two-step mapping method which is to first gather a passing variable into the global domain, and then to distribute it into each sub-domain. Dry points in SWAN are set to be wet with a small water depth (1 mm) in order to make an equal split of a computational domain.
Fig. 2 shows an example of domain decomposition in SWAN and SHORECIRC.
To investigate performance of the parallel program, numerical simulations of an idealized case are tested with different numbers of processors on a Linux cluster located at University of Delaware. The test case is set up in a numerical grid of 1800 \(\times\) 1800 cells. Fig. 3 shows the model speedup versus number of processors. It can be seen that performance scales nearly proportional to the number of processors, with some delay caused by inefficiencies in parallelization, such as inter-processor communication time.
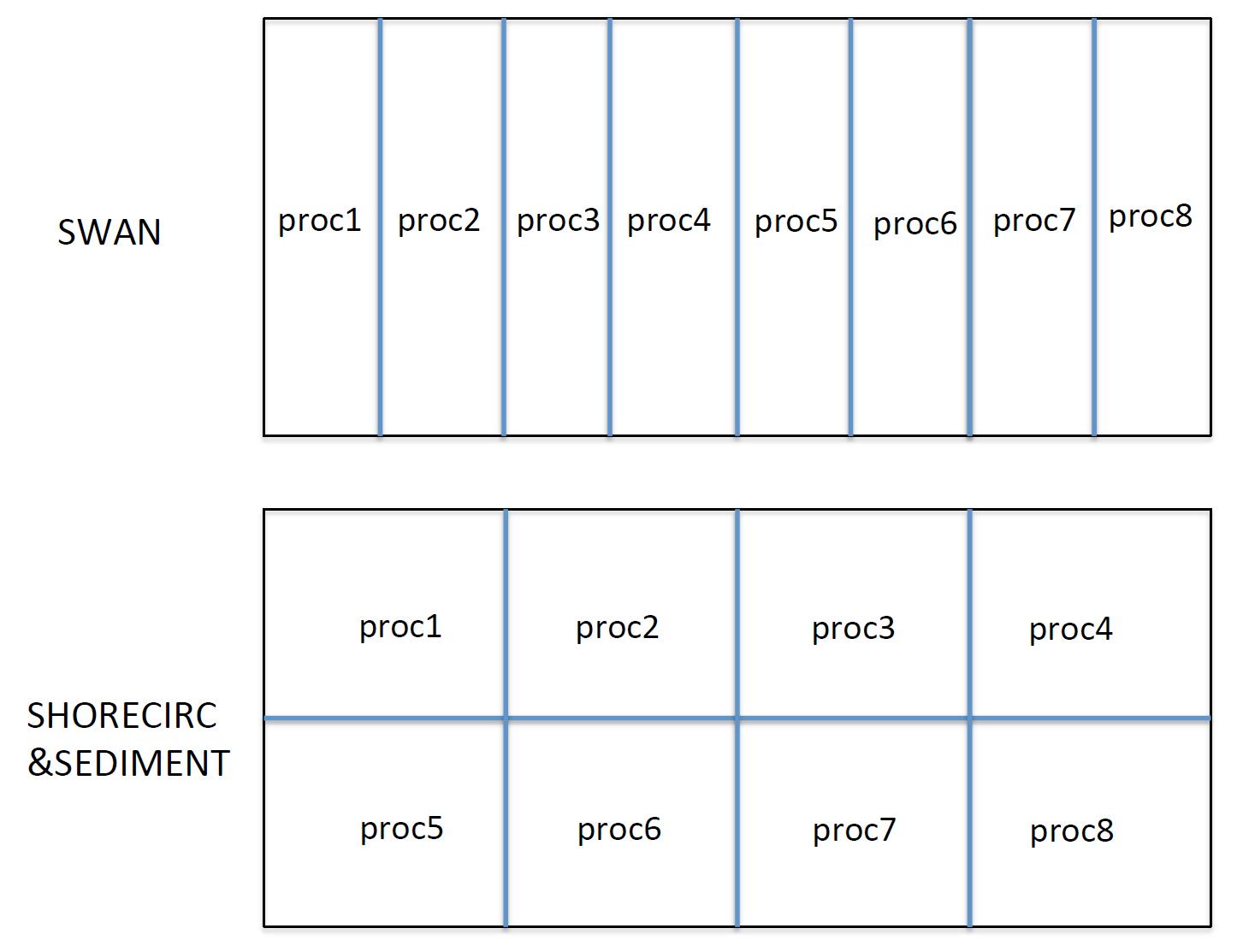
Fig. 2 An example of domain decomposition in SWAN and SHORECIRC/SEDIMENT.¶
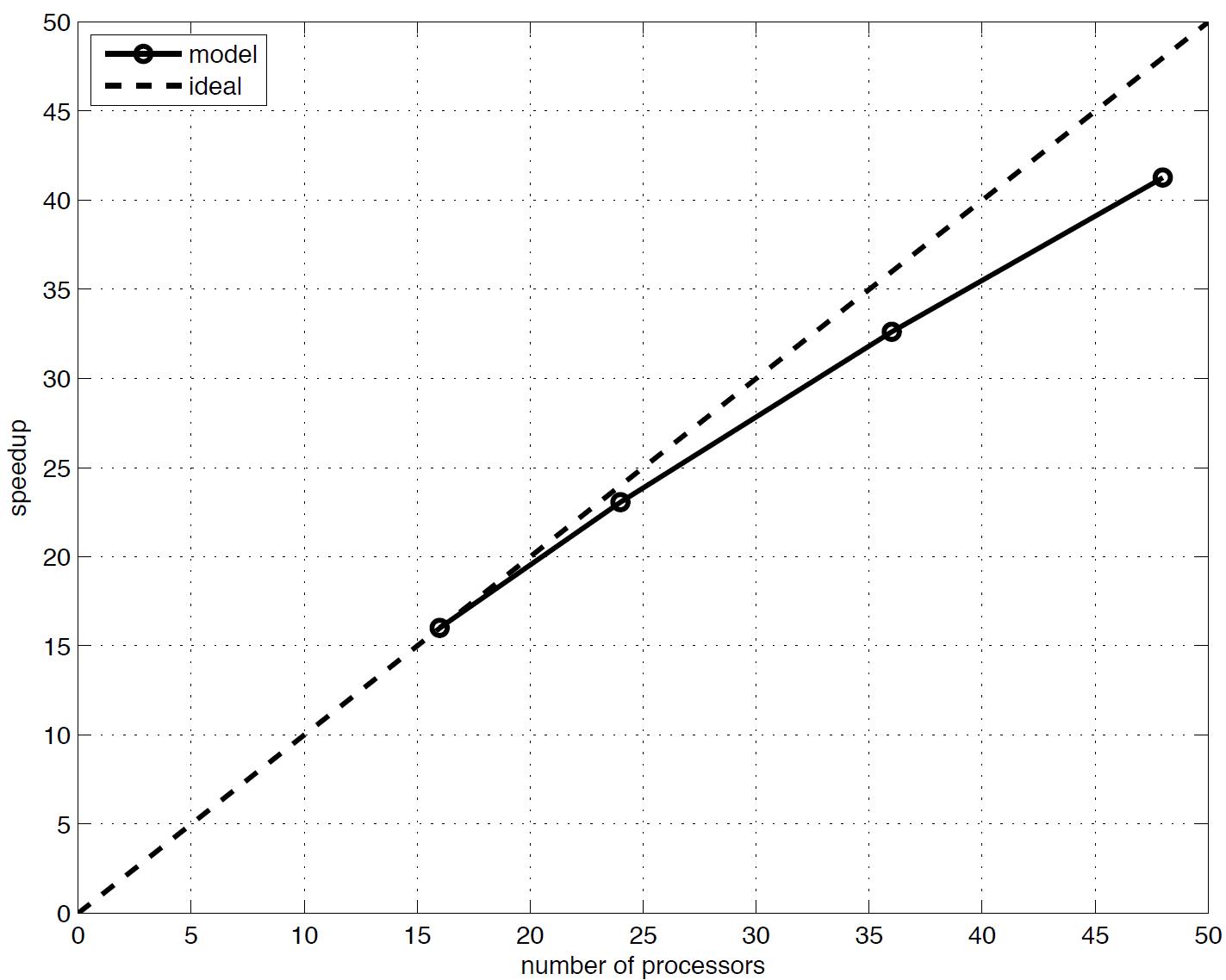
Fig. 3 Variation in model performance with number of processors for a 1800 x 1800 domain. Straight line indicates arithmetic speedup. Actual performance is shown in the curved line (the figure needs to be updated using the coupled model !!!).¶